
AI is the next interface

AI is the human-computer interaction model we've been dreaming of since the idea of automation crossed our minds. It will not only replace ubiquitous interaction concepts like the mouse but also render 80% of today's software obsolete. GIGO: Garbage in, garbage out, is dead. That's a good thing.
Before modern computers, before Babbage's analytical engine, the question was always: how can humans interact with a device that automates or mechanizes what otherwise would take time and effort?
This is an old, old dream. Homer defined the gates of heaven in the Iliad as αὐτόμαται (automata), self-moving, driven by divine power. Every technological step we've taken for the last 3,000 years has been in pursuit of those pearly, self-opening gates. The dream of a self-driven process, with our thoughts and desires as the primary drivers, is what has driven the excitement for new technological progress. So here we are. Well, where are we exactly?
Of mice and computers

It's serendipitous that it's been almost exactly 50 years since the invention of the graphical user interface by Engelbart and the team at Xerox PARC. 5 years before, Engelbart presented what we today have nicknamed The Mother of All Demos, an introduction to the NLS - or oN-Line System -, a suite of tools that today are ubiquitous: hypertext links, raster graphics, windows, and the mouse.
Windows, and graphical interfaces, were created for 2 purposes: increasing the density of displayed information and contextualizing user input. Before that, information density was limited to character compositions, and user input's context was limited to the directory they were navigating and the vocabulary allowed by the system. Graphical interfaces allowed for symbols, structures, information hierarchy, and eventually colors, that present abstractions with higher information embedded in them. The mouse allowed for user input connected to the location of this information, with more intuitive expected outcomes and, again, a considerable amount of context.
Eventually, we invented touch screens – first resistive and then, thank God, capacitive – to minimize the amount of space, muscle memory, and motor skills needed to interact with buttons and other visual cues.
The perfect user of an ERP is a robot, not a human
Things are easy to use when the system is simple. No one struggles with Solitaire or Minesweeper because the inputs and the outputs are simple. Very few people struggle with word processors because again, the mission is as clear as the interaction model: you write, click around, to fill a virtual blank canvas with words.
The problem comes with complex systems: those highly relational, business process-dependent, software suites that make the business world run. CRMs, ERPs, CMSs. They are hard to use because they contain vast amounts of knowledge organized in complex ontologies. The perfect user of an ERP is a robot, not a human. The amount of context required to perform a business process efficiently in a modern ERP or CRM is vast and interconnected.
Well-designed complex systems rely on visual cues and information hierarchy to: tell the user where they are, the information they need, and the expected outcome of their task. The problem is that most software systems are not well-designed. There's an undue emphasis on the visual and teams forget the strictly functional and situational. If form follows function, function follows situation, especially when we're talking about SaaS and B2B in general. Not all users are concentrated, focused, and sitting at a desk. Some are running, at a warehouse, in noisy environments, on their feet, without surface area for a mouse or patience for a touch screen.
AI, the fuzzy input interface
OpenAI may have inadvertently, or not, launched an AI product that is advanced and functional enough to become the next interface paradigm for software. In fuzzy environments like the ones I described above, it simply is too difficult to design the perfect UX model, with a UI that has the right information architecture and hierarchy for all the user needs and permutations.
Most business processes are too complex to begin with, which is something I've been studying for a very long time and I'm excited to one day write about. To summarize, imagine poorly translating the requirements of a business process into a graphical abstraction of data that is highly relational, to begin with. There's a whole industry dedicated to re-skinning mainstream systems like SAP and Jira, albeit some do it quite poorly.
I think it's that simple: AI is the solution to replace 15 clicks, 4 buttons, and 3 poorly implemented text searches. I've seen a lot of excitement in the last few weeks about using AI as a backend to processes, but in my opinion, the real potential right now is using it as a frontend.
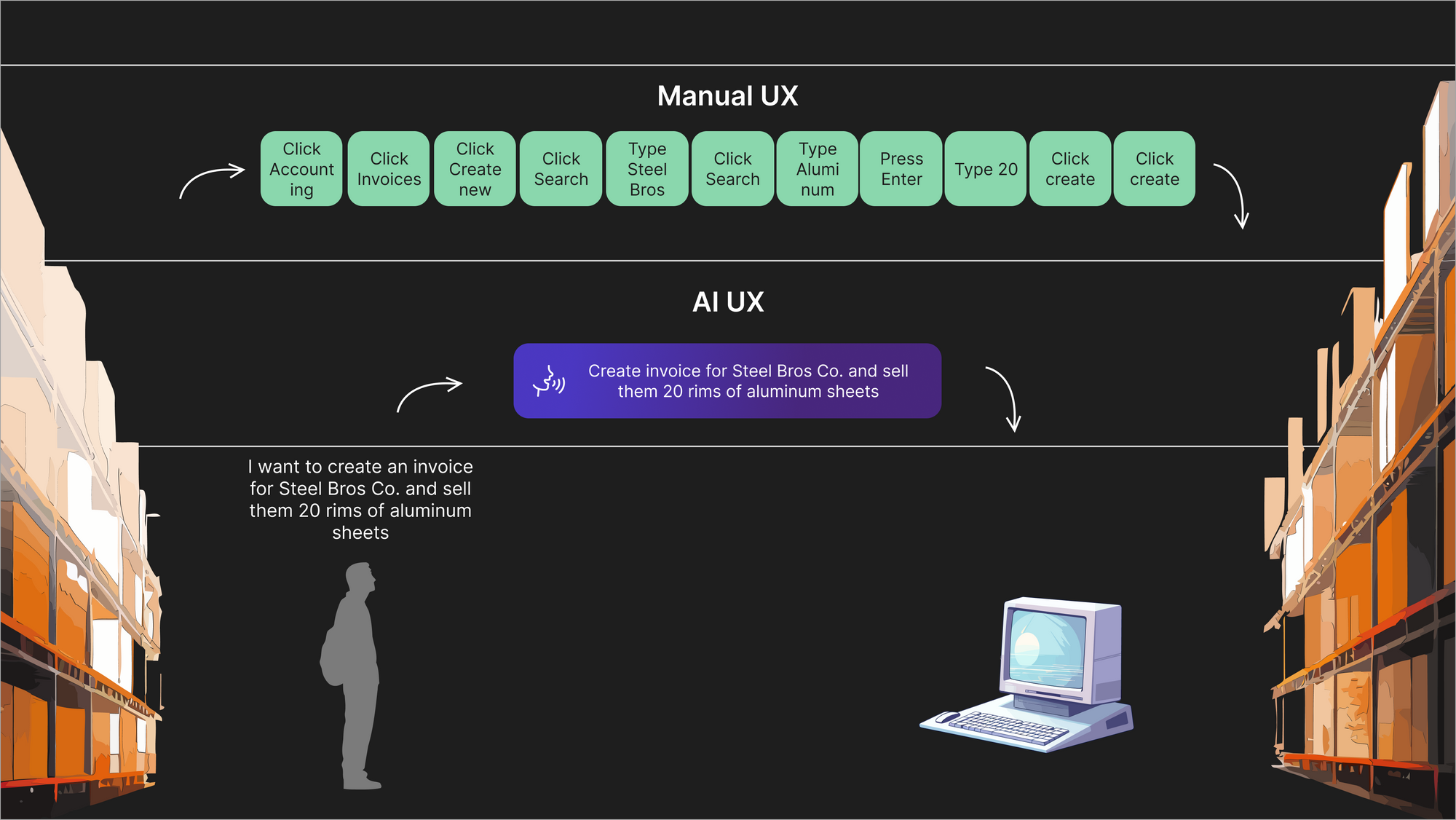
The goal of UX should be to make the translation between our desires and a mechanized environment as seamless and simple as possible. There are no gotchas here. This is why command palettes work. LLMs are the perfect translation layer between thoughts and expected outcomes in environments where the user can express input in language, whether written or spoken. If you could create a rule-based environment with thousands of parameters, you would certainly improve the UX of a complex system, but now you don't need to: LLMs are effectively environments with billions of rules, complex enough to extrapolate between fuzzy inputs and deterministic outputs.
The example above is overly simplified, of course. LLM outputs don't replace the density of screens, so consider an LLM in this use case the replacement for a mouse and a keyboard.
Caveats
Not everything is roses, and there are a few caveats to this approach that technology should hopefully resolve with time and patience.
- Information density: as just mentioned, textual language expression doesn't contain as much density or speed as a graphical interface. The speed at which the user can process spoken or read information is much slower than a properly designed UI. That's why I don't think LLM outputs, as of yet, replace a traditional UI but complement it.
- Context/knowledge retention: the LLM, or the system enveloping it, needs enough context for the example above to work. LLMs by definition don't know who your customers are. They are strictly stateless. There are ways, some more sophisticated than others, to introduce stateful context:
Few-shot learning: in other words, the knowledge retained by the LLM is spontaneous, session-limited, and strictly contextual. The LLM needs to be fed all possibilities of relevant context on every request, and that is computationally expensive. OpenAI charges per token, which makes this approach impractical at enterprise scales and very expensive. As things progress, I'm sure we'll be able to fine-tune LLMs like Chat GPT-4, and I'm certain the future of LLMs in mainstream business is knowledge and process specialization, but for now, we're limited. You can, however, fine-tune other OpenAI models and the results in complex environments are limited. There's a clear difference between training a model with user-specific data vs. with system-wide data all users can leverage.
Symbolic representations: Without getting into too much detail, LLMs are particularly well suited for symbolic language. They're, after all, compression engines. The personality of an LLM, if that's a concept we're willing to concede, would be that of a Gestalt system. LLMs are configurationist automata, extremely good at a cloze test. Using symbolic references allows us to embed more information in system/behavior design prompts. The LLM outputs from these symbolic representations can be then fed back into a database lookup to fetch only the strictly relevant information. It is slow, though.
Knowledge retention is essential and by far the biggest limitation in these systems. Some companies are working on this, with varied results, being the easiest approach using calculated few-shot learning. - LLMs are not intelligent: there's a joke concept in Spain called a cuñado – a brother-in-law – a know-it-all who confidently parrots back things they've read on the Internet, some of them frequently wrong. LLMs are cuñados. Their intelligence is limited to drawing extrapolations from language and symbols. We perceive them as intelligent because humans tend to express their intelligence through the use of language. Proof of this is that LLMs frequently "hallucinate", especially in environments with poor context and a lot of entropy.
The potential is incredible // and a sneak peek of a hobby project
I'm personally focusing my interest in AI in human-computer interaction. I still think LLMs are incredible frontend machines if designed correctly, and technology is only going to make them more coherent and faster.
I wrote this very article with a little hobby project I've been building using Chat GPT and Whisper. I use this for writing articles and emails because I can write much better when I'm dictating.
If you're building something amazing, hit me up. I love brainstorming ideas. And remember, stay away from the noise: real progress is achieved through discipline and perseverance, not tweets.