
Practical AI: AI for Enterprise, complex ontologies, and lots of data

also titled Do Androids Dream of Vectorized Ontologies?
A recurring conversation I've had with friends building in the AI space is how to get started using LLMs in enterprise environments. The use cases are extensive, from transcribing and summarizing large amounts of data to drawing conclusions and sparking insight. (More on sparking later). What's clear is that in order to extract value from AI, we need to dissect a company's ontology, not just its data.
Recap: LLMs with large data sets
In other words, not everything fits in a single, short, simple ChatGPT prompt. There are 2 main paths to feed LLMs large amounts of data today:
- You feed it the entire data set in prompt time. This is akin to copy-pasting the entire data set relevant to the questions you want to ask. For many use cases, this is impractical and expensive. Anthropic's Claude model has context windows of up to 100k tokens, i.e. you can feed it about 5 hours of text. (This would cost you $0.16 on their lighter model and $1.10 on their superior one, per call). This is also called "few-shot learning".
- You store the data and retrieve it in prompt time. This is where vector databases come into play. The idea is that you take your data, separate it into semantically meaningful chunks, get a vector for each that represents its position in the semantic space of your choice, and store the vector results. When the user submits a prompt, you pass on the prompt to the vector database and retrieve results semantically connected to the prompt, then feed them to the LLM and ask it the question you want. Some well-known vector DBs today are Pinecone, Weaviate, Qdrant, and Chroma.
Example:
- McDonald's wants to generate an executive summary for the board about customer reviews regarding the cancelation of all-day breakfast. (They have 450k worldwide reviews from the last quarter)
- They vectorize all reviews and store them in a vector database.
- They ask for "reviews about all-day breakfast canceled" to the vector database and get the first 100 results.
- They feed them into ChatGPT, then ask it to generate an executive summary from the extracted reviews.
Neither of these 2 alternatives is the panacea. As I mentioned, feeding all 450k reviews to an LLM in prompt time is impractical and expensive (also for most models, not possible yet). On the other hand, vector database workflows slow things down and also force you to narrow down the problem: you may have seen in the example above we're retrieving only the top N results. Also, what happens if we miss things? We made a conscious choice to chunk out data in the storage step, so we don't get a full picture of our entire data set and neither will the LLM.
There's a 3rd choice, the ideal fantasy in my opinion, which is to custom-train an LLM with your own data. This is only feasible if: a) you know how to do that, and b) you have the budget for it. Good news: you're McDonald's. You fire up Mosaic. You can spend $200k-$500k training your own LLM with company data on top of open-source data sets. However, you do need to progressively update it with new data, so that's another $200k every time you update it. Not terrible for a company with millions of daily customers but unattainable for most companies on Earth, even at enterprise levels.
Ultimately, I think vector databases will become an intermediate tool to train your own LLMs, rather than an isolated tool you use to extract information for the purposes of few-shot learning. For this to happen we need the costs of ML computing to significantly go down – but if this happens, we may encounter LLMs with contexts of millions of tokens be extremely cheap.
As of today, the best option for most cases is to leverage vector databases.
Enterprise AI will be about ontologies, not just data
A problem I've been working on for some time now is: how do you weave everything together? LLMs are static black boxes and the output's value will be proportional to the quality of the data and the prompt.
I've seen companies starting to tinker with it in isolated processes, such as customer support communication and code, but the real value will come when we tie everything together. One thing is for sure, though: you can't express a company just with data. If we want to extract all the juice we can, we need to express a company in its ontological components:
- Concepts: Franchises, Menu items, Orders, Customers
- Relationships: Orders contain menu items, how concepts and instances are related to one another
- Functions: Purchasing, Frying (abstractable modular business processes)
- Instances: Individuals of concepts, such as Diet Coke or Bacon Cheeseburger
- Axioms: Statements that are asserted to be true in the company's domain
The thing is, ontology as a branch of metaphysics is incredibly powerful at describing sources of truth. A company is incorporeal but terribly complex. This is not very different from BPM, as I mentioned in a previous post, where you express business processes and stakeholders as a function of inputs, decisions, and expected outcomes. It's another perspective.
There are ways to express an ontology in a standardized way, such as OWL. When you read about Tim Berners-Lee's thoughts on the Semantic Web, you sense a slight regret in which the original Web was built. I have opinions on this that are probably worth a long rant in a separate post.
I mentioned in a previous post that I strongly think most companies' time is spent structuring and destructuring data for different purposes and that the lowest-hanging fruit is to stop people from spending their time doing this so they can spend it on making decisions and doing higher quality work. Well, I think to do that, we need to start mapping out companies through their ontologies, not just their data, and using that to drive LLMs.
The metadata
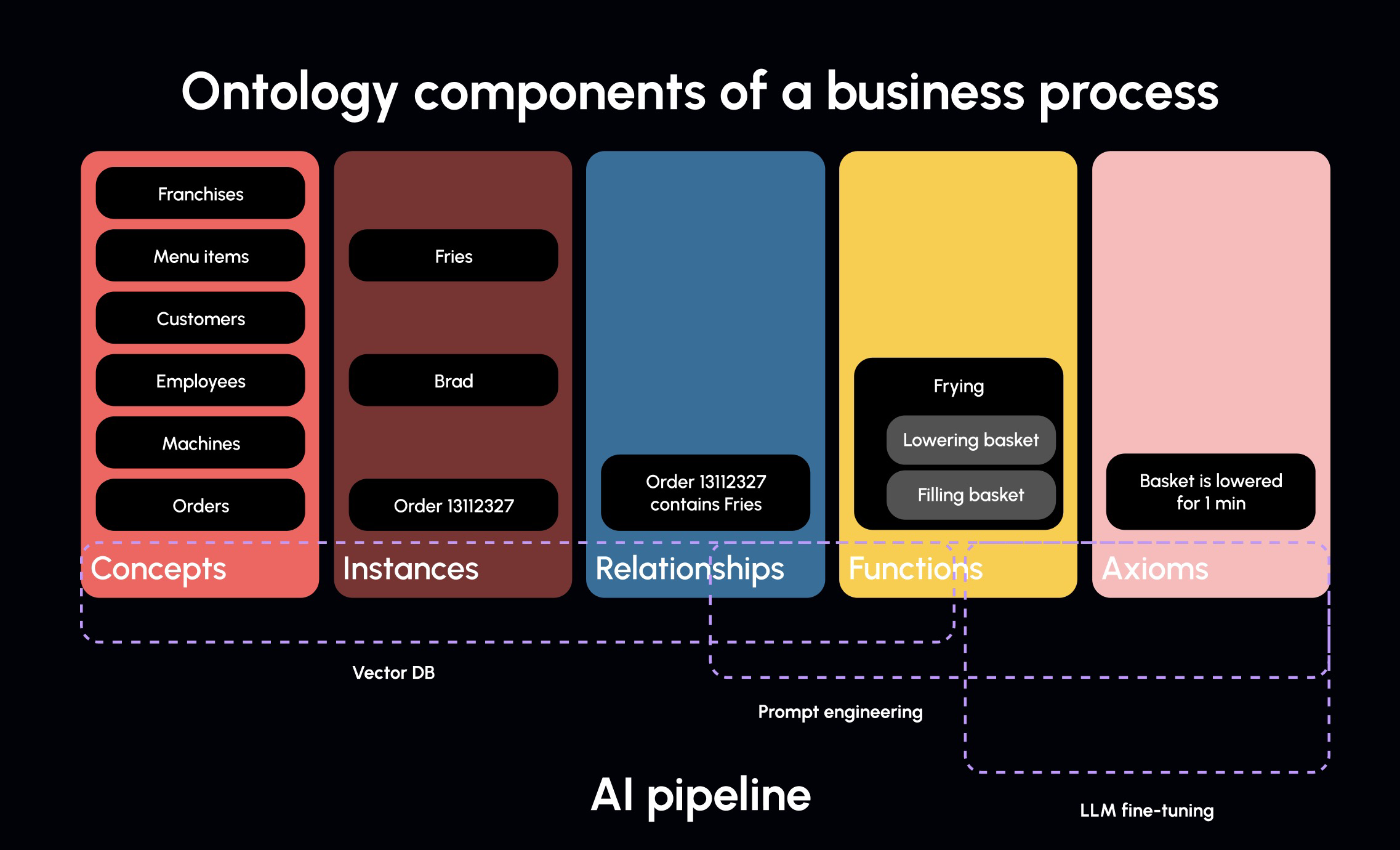
I'm arguing that instead of overloading prompt engineering for functions and axioms in your company, such as verbose explanations of your company's processes, we should standardize company ontologies and express them in data, metadata, and heavily store and vectorize them. In other words, you express business processes, functions, and relationships in the vectorized data itself, so it's ready for retrieval and usage.
The first response I've gotten is: this is a lot of work and we don't have time for this. I agree. There's a silver lining: to the extent that LLMs represent an abstraction of intelligence, they're very good at extracting ontologies from unstructured data. In other words, AI can help you discover the best data structure to better use AI.
One more thought
As I write this, OpenAI just announced they now support fine-tuning their GPT 3.5 - Turbo model. In their own words, this doesn't replace the retrieval of data (via vector DBs or otherwise). It does simplify expressing axioms and functions in your company processes. As always, I encourage tinkering. I know I'll be playing with it this week.
Additional notes after publishing:
- Another limitation of vectorizing semantics is understanding what those semantics are, to begin with. The mainstream approach of just using a widely available model to vectorize is good, but very specific use cases may require custom vectorizing models. Even the best model can't replace an in-depth analysis of what should be vectorized, and what can just be stored plainly.